The 3-Year Journey to an Actually Good Monitoring Stack
Phare.io’s uptime monitoring has been rebuilt many times, from AWS Lambda to cloud workers, and now Docker on the edge. Each version came with hard lessons, last-minute rewrites, and unexpected scaling challenges. Here’s the full story of what worked, what broke, and what finally feels solid.

When I started building Phare in early 2022, I planned the architecture assuming that fetching websites to perform uptime checks would be the main scaling bottleneck, and oh boy, was I wrong. While scaling that part is challenging, this assumption led to suboptimal architectural choices that I had to carry for the past three years.
Of course, when you build an uptime monitoring service, the last thing you want is your monitoring infrastructure to be inefficient, or worse, inaccurate. Maintenance and planning take priority over everything else, and your product stops evolving. You're no longer building a fast-paced side project, you're just babysitting a web crawler.
It took a lot of work to fix things while maintaining the best possible service for the hundreds of users relying on it. But it was worth it, and the future is now brighter than ever for Phare.io.
Let’s go back to an afternoon in the summer of 2022, when I said to myself:
Fuck it, I’m going to make an uptime monitoring tool and compete with the 2,000 that already exist. It should only take a weekend to build anyway.
(It was probably in French in my head, but you get the idea).
The very first version: Python on AWS Lambda
AWS Lambda immediately felt like a perfect fit. I had written a few Lambda functions before, and it seemed like a good choice to easily run code in multiple regions, with the major benefit of no upfront costs and no maintenance. Compared to setting up multiple VPSs, with provisioning and maintenance on top, the choice was clear.
I wrote the Python code for the Lambda, and all that was left was to invoke it in all required regions from my PHP backend whenever I needed to run an uptime check.
The AWS SDK supports parallel invocation, which solved the problem of data reconciliation. I had the results of all regions in a single array and could easily decide if a monitor was up or down, sweet.
$results = Utils::unwrap([
$lambdaClient->invokeAsync('eu-central-1', $payload),
$lambdaClient->invokeAsync('us-east-1', $payload),
$lambdaClient->invokeAsync('ap-south-2', $payload),
]);
Most of the business logic was built on top of that result set. How many regions are returning errors? How many consecutive errors does this particular monitor have? Is an incident already in progress? Should the user be notified? etc. (As you guessed, this becomes important later.)

This setup worked well, delivering accurate and reliable uptime monitoring to the early adopters of Phare, while I focused on building incident management and status pages.
Until May of 2024, when I received a ~25 euro invoice from AWS. Okay, that’s not much, but that was for only 4M performed checks. That’s the cost of five entry-level VPSs, all to monitor about 100 websites. Not cost efficient at all.
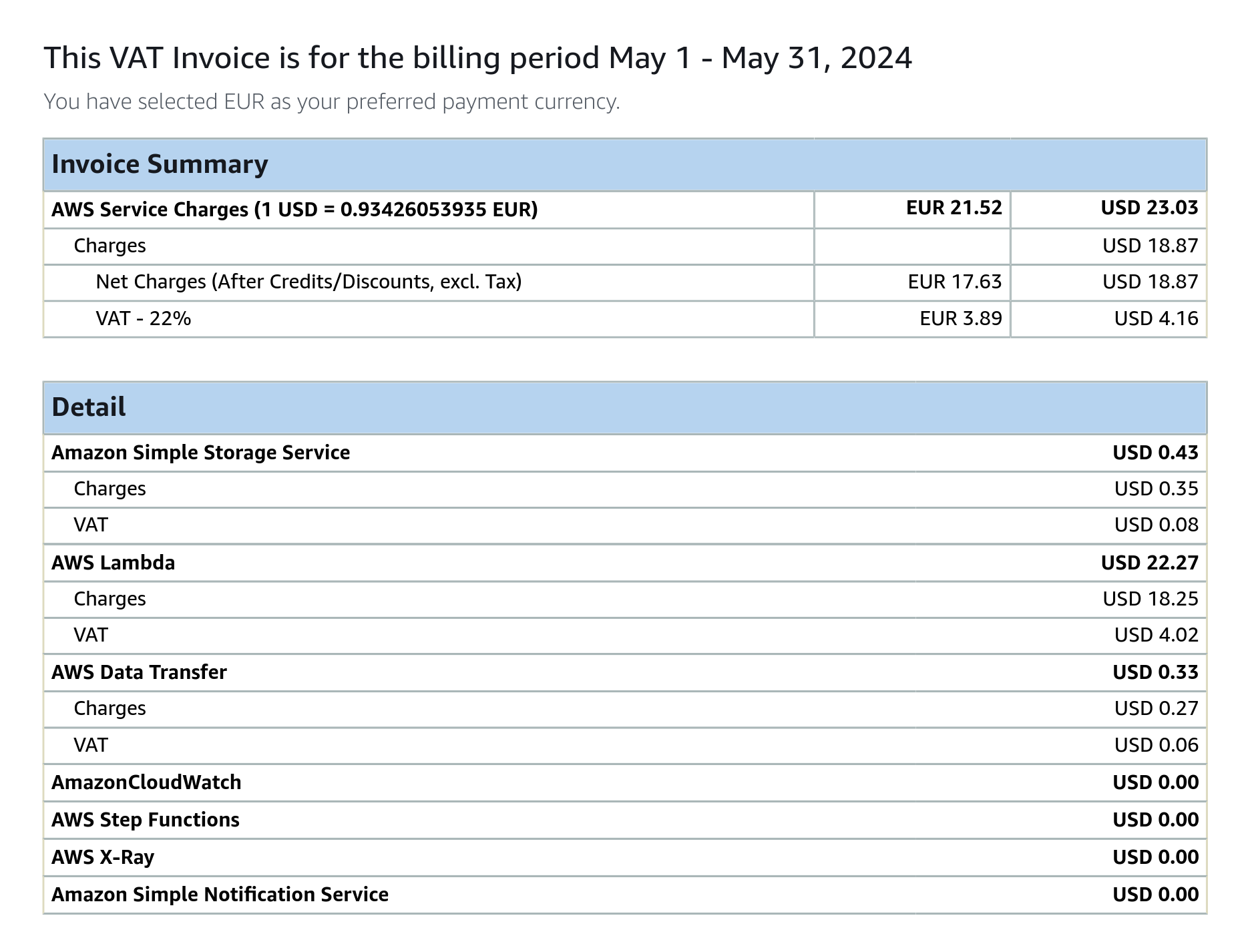
The biggest part of the spending was from Lambda duration (GB-Seconds). As Phare’s user base grew, websites got more complex, no more just monitoring my friends’ single-page portfolios with 100 out of 100 Lighthouse scores. Websites can be slow, and even with a 5-second timeout, the Lambda execution ended up being far too expensive.
Another issue was request timing accuracy. AWS Lambda lets you select the memory limit from 128MB to 10GB, and with more memory comes more CPU power. To fetch a URL with realistic browser-like timing, the Lambda needed at least 512MB of memory, a significant cost factor for longer checks, and a huge financial attack vector.
It was time to find an alternative.
Enter Cloudflare Workers
Cloudflare Workers seemed unreal, much cheaper than AWS Lambda, and you only pay for actual CPU time. That meant all the idle time waiting for timeouts was now completely free. I could build the cheapest uptime monitoring service while keeping a good margin, and offer an unbeatable 180 regions.
Setting it up wasn’t straightforward. On top of having to rewrite the code in JavaScript, it was not possible to invoke a Worker in a specific region. And that was a major blocker.
After many failed attempts, I came across a post from another Cloudflare user who had figured out how to do exactly that, using a first Worker to invoke another one in a chosen region. It wasn’t documented, but Cloudflare seemed aware of this loophole for a while, with no public plan to restrict it. The performance and pricing were too good to ignore, so I went with it. YOLO.

The two-Workers technique changed everything. I could send large payloads of monitors, have the first Worker create smaller regional batches, and return reconciled results. My backend became more and more dependent to the way Cloudflare Workers behaved.
Of course, there were limitations: non-secure HTTP checks were a no no, it was impossible to get details on SSL certificate errors, and TCP port access was restricted. But I managed to find a few workarounds, and everything was running smoothly.
The ecosystem was growing fast, edge databases and integrated queues were being released by Cloudflare, my workers averaged sub 3ms execution times. The future looked bright.
Of course, after just a few months, on November 14th, 2024, regional invocation was patched, and the entire uptime infrastructure went down. That day was a looong day.

I quickly patched the script, rerouting all requests to the invoking region so uptime checks still ran, even if not in the right region.
It was time to find an alternative. Fast.
Bunny.net Edge Scripts to the rescue
At that time, Bunny.net had just released their Edge Scripts service in closed beta, a direct competitor to Cloudflare Workers, built on Deno. Pricing was similar, and the migration looked plug-and-play, which was all that mattered, because I couldn’t afford the time to rewrite the backend logic.
I got into the beta, rewrote the script in Deno using the same two-invocation strategy, and began rerouting traffic from Cloudflare to Bunny.
The first part of the migration went smoothly, regional monitoring was back up, and I could finally relax a bit.
Of course it wasn't long until shit hits the fan, and the uptime monitoring performance data started to get funky. Cloudflare was a more mature solution that handled many things in the background, like keeping TCP pools in an healthy state, which is important when you perform thousands of requests to different domains.
Thankfully, Bunny’s technical team was amazing. They helped me a lot, and I gave them plenty to work on in return.
Eventually, things got better. Edge Scripts left beta and became generally available, and that’s when a new bottleneck appeared.
The backend code was still invoking Edge Scripts and waiting for a batched response. As Phare gained new users daily, the number of invocations grew. My backend started hitting 502/503 errors on Bunny’s side. Queue wait times forced me to increase concurrency. And I was still facing the same limitations I previously had with Cloudflare Workers.
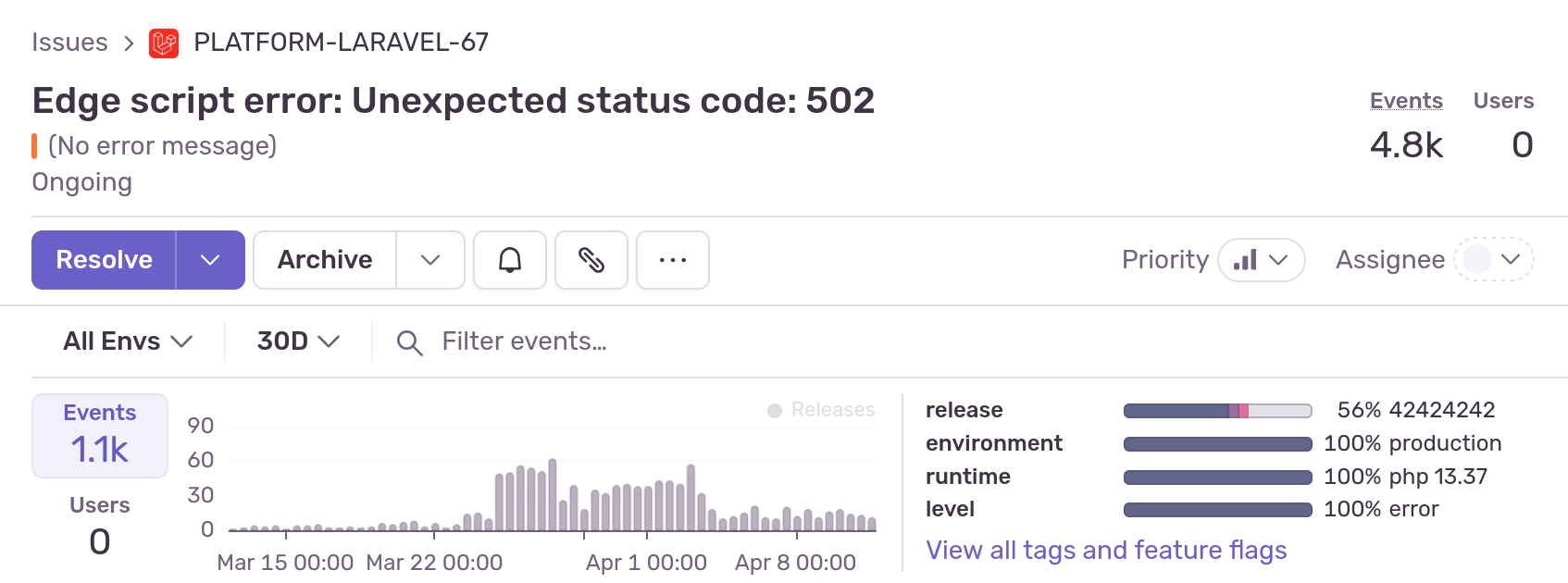
Maybe Edge Scripts weren’t the best long-term solution after all.
I knew what I had to do from the beginning: decouple the backend from the edge scripts and process results asynchronously. But doing so meant reworking the deepest, most fundamental part of my backend logic, now massive after years of accumulated features.
Again, I had no choice if I wanted to keep improving Phare.
It was time to find an alternative.
The obvious answer: Bunny Magic Containers
In early 2025, Bunny announced Magic Containers, a new service letting you deploy full Docker containers across Bunny’s global network. I had been desperately trying to find a European hosting provider with such a diverse range of locations. I was already integrated with the Bunny ecosystem, and had full confidence in their amazing support team.
This time, I did things slowly. I built a few preview regions to test at scale with real users, in parallel with the still-working Edge Script setup. Of course this meant running two versions of the backend logic at the same time, two different ways of triggering monitoring checks, and thousands of new line of code to make it work. Not fun, but necessary to finally fix the past mistakes.
The new uptime monitoring agent would run continuously in a Docker container, billed by CPU and memory usage. Cost was a major concern, so I rebuilt it in Go with the following goals:
- The Phare backend and the monitoring agent must be fully decoupled.
- The agent should fetch its monitor list from an API, no backend push.
- Results are sent asynchronously to the backend.
- Data exchange should be minimal.
- The agent must be fault-tolerant and self-healing.
- It should match the feature set of the Edge Script version.

And just like that, six new preview regions were added to Phare at the end of February, and they ran like fine clockwork. I actually went on vacation a few days after the release, for a full month, and didn’t have a single issue. I did have a lot of time to reflect on my past mistakes.
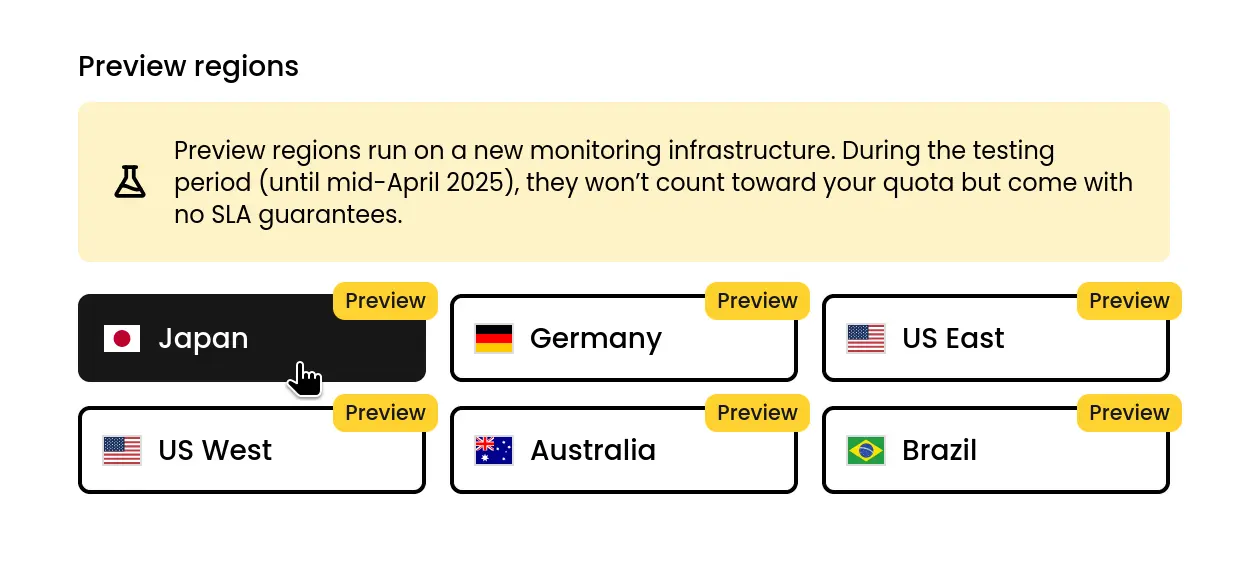
I won’t go into too much detail about the new infrastructure, this post is painfully long enough already. Today, all checks run on Bunny Magic Containers. And for the first time in years, I can focus on building new features for both, the agent, and the platform.
And if I ever need to change provider again, I can just spin up a few VPSs with my Docker image and it’ll work. I should’ve done that from the beginning, but I wanted to go fast, and that costed me a few years of real progress.
What’s next
The current infrastructure works well, but it’s not perfect. When a container is restarted there's a brief overlap where two instances might run the same check. If a region goes offline, there’s no re-routing, users need to monitor from at least two regions to stay safe.
Fetching the monitor list every minute via API works surprisingly well, thanks to ETags and a two-tier cache system. But I’m still exploring how to reduce HTTP calls. Having read replicas closer to the containers might be the best bet.
From the outside, it didn’t look so bad, Phare grew to nearly a thousand users during all this infra chaos. Users loved the quality of the service far more than I did.
This post is mostly a rant at my past self. I took too many shortcuts while building what started as a weekend project, which held the company back once it grew beyond that. But maybe that’s what startups are all about.
That said… see you in three years for the blog post about Phare.io Monitoring Stack v8, probably rewritten in Rust, because history repeats itself.